Annotation Tool
Annotation interface for efficient multi-field labeling and human verification.
A Multi-Level Emotion-Annotated Dataset of AI-Generated Images
AI-generated images (AIGI) have emerged as a dominant form of visual media; however, the emotional responses they elicit in human observers remain largely underexplored. Existing affective image datasets mainly focus on natural images and do not provide sufficient support for studying emotion in AIGI. To address this gap, we present AIGIEmo, an emotion-annotated dataset for AI-generated images. The dataset contains 160,000 images, balanced across eight emotion categories, and includes both categorical emotion labels and continuous valence--arousal annotations. In addition, AIGIEmo provides rich multimodal metadata, including image captions, reasons for emotion, visual style, scene type, object information, facial expressions, human actions, and low-level visual attributes such as color and brightness. To improve annotation quality, we use human annotation for emotion labels and machine-assisted pre-annotation for non-emotion fields. We further analyze the emotional distribution, affective consistency, and visual-textual properties of the dataset, showing that AIGIEmo offers class-balanced affective structure and diverse multimodal annotations. AIGIEmo provides a useful resource for studying emotional responses to AIGI and supports future research on affective understanding, analysis, and reasoning of AI-generated images.
Existing visual emotion analysis (VEA) datasets mostly focus on photos or art, while current AIGI resources remain small or miss key supervision such as V-A scores, emotion attributes, reasoning, and captions. AIGIEmo brings these signals together in one balanced dataset.
| Dataset | Image Type | Label Source | Domain | #Images | Emotion Categories | V-A Scores | Emotion Attributes | Emotion Reasoning | Caption |
|---|---|---|---|---|---|---|---|---|---|
| IAPS | Photo | H | Photo | 395 | ✓ | ✓ | × | × | × |
| GAPED | Photo | H | Photo | 730 | ✓ | ✓ | ✓ | × | × |
| ArtPhoto | Art | H | Art | 806 | ✓ | × | × | × | × |
| Emotion6 | Photo | H | Photo | 1,980 | ✓ | × | × | × | × |
| FI | Photo | H | Photo | 23,308 | ✓ | × | × | × | × |
| WEBEmo | Photo | H | Photo | 268K | ✓ | × | × | × | × |
| ArtEmis | Art | H | Art | 80K | ✓ | × | × | ✓ | ✓ |
| EmoSet | Photo/Art | H+M | Photo/Art | 3300K | ✓ | × | ✓ | × | × |
| FindingEmo | Photo | H | Photo | 25K | ✓ | ✓ | × | × | × |
| EmoArt | Art | H+M | Art | 132,664 | ✓ | ✓ | ✓ | × | ✓ |
| EmoConveyance | AIGI | H | AIGI | 60 | ✓ | × | × | × | × |
| AIGI-VC | AIGI | H | AIGI | 2,500 | ✓ | × | × | ✓ | × |
| LAI-GAI | AIGI | H | AIGI | 847 | ✓ | × | × | × | ✓ |
| AIGIEmo (Ours) | AIGI | H+M | AIGI | 160K | ✓ | ✓ | ✓ | ✓ | ✓ |
Compared with prior datasets, AIGIEmo is designed specifically for AI-generated images while providing a more complete combination of affective labels, auxiliary attributes, reasoning targets, and captions.
| Dataset | MTLD ↑ | Entropy ↑ | Word Count ↑ |
|---|---|---|---|
| Flickr30K | 11.93 | 3.31 | 12.34 |
| ArtEmis | 15.31 | 3.67 | 15.89 |
| COCO Caption | 10.18 | 3.16 | 10.47 |
| EmoArt | 16.34 | 3.67 | 16.22 |
| AIGIEmo Caption | 68.76 | 4.44 | 27.98 |
| AIGIEmo Reason | 59.04 | 4.78 | 46.63 |
Mean lexical statistics of textual annotations.
Annotation interface for efficient multi-field labeling and human verification.
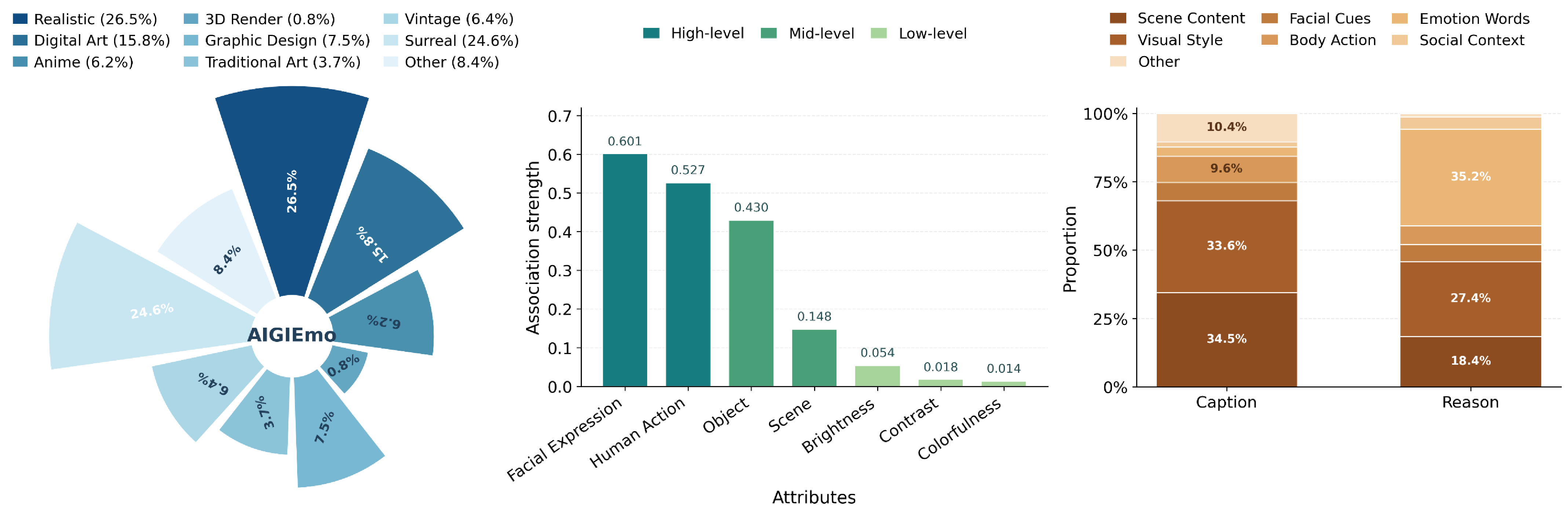
Left: style-family distribution. Middle: attribute-emotion association. Right: semantic cue proportions in captions and emotion reasoning.
Continuous: ε² = (H - k + 1) / (n - k)
Categorical: V = sqrt(χ² / (n · min(r - 1, c - 1)))
High-level semantic cues are stronger than low-level visual attributes.
Backbone and shared neck with emotion and V-A branches, plus gated auxiliary attribute cues.
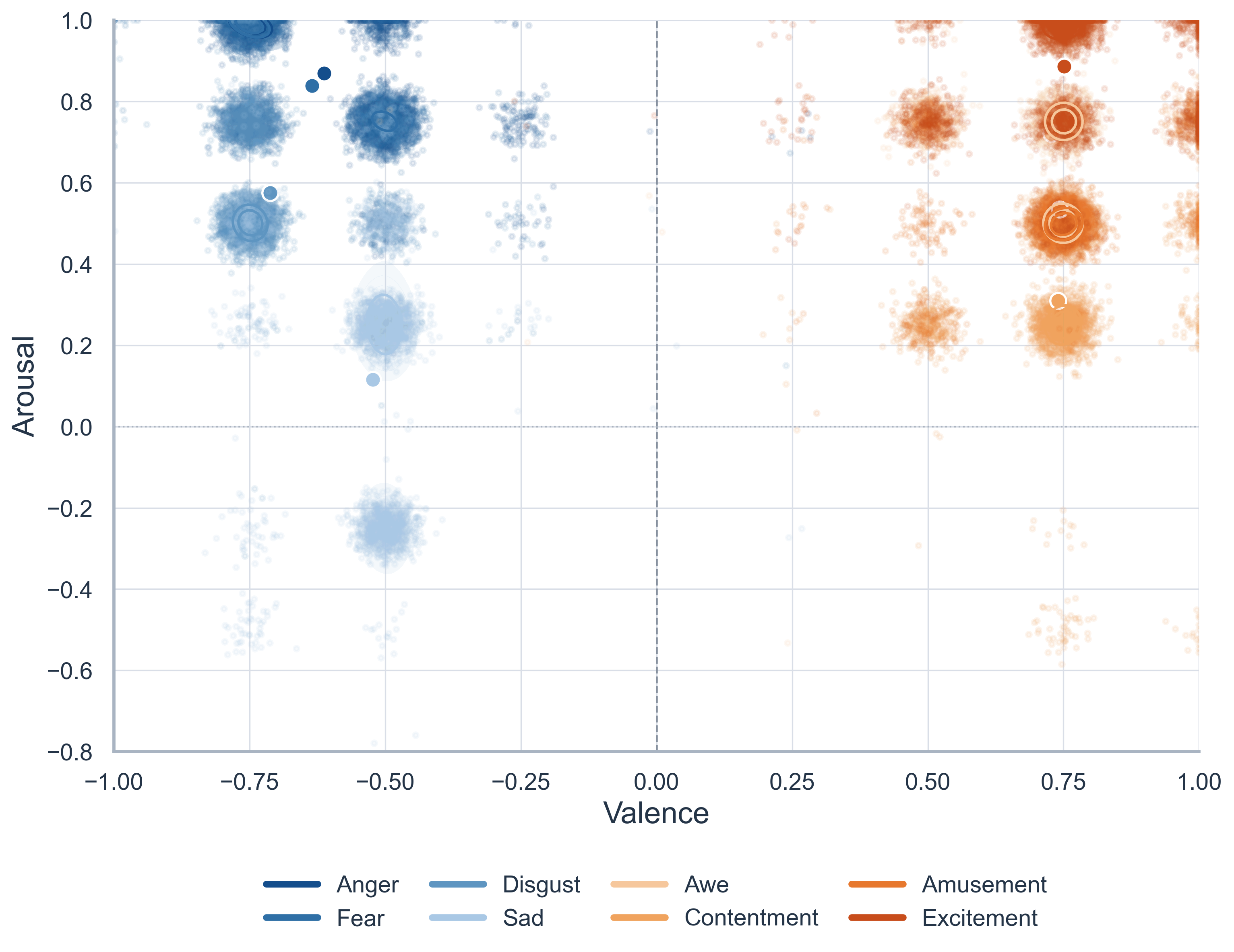
Emotion categories form a clear structure in valence-arousal space, with positive and negative groups well separated.
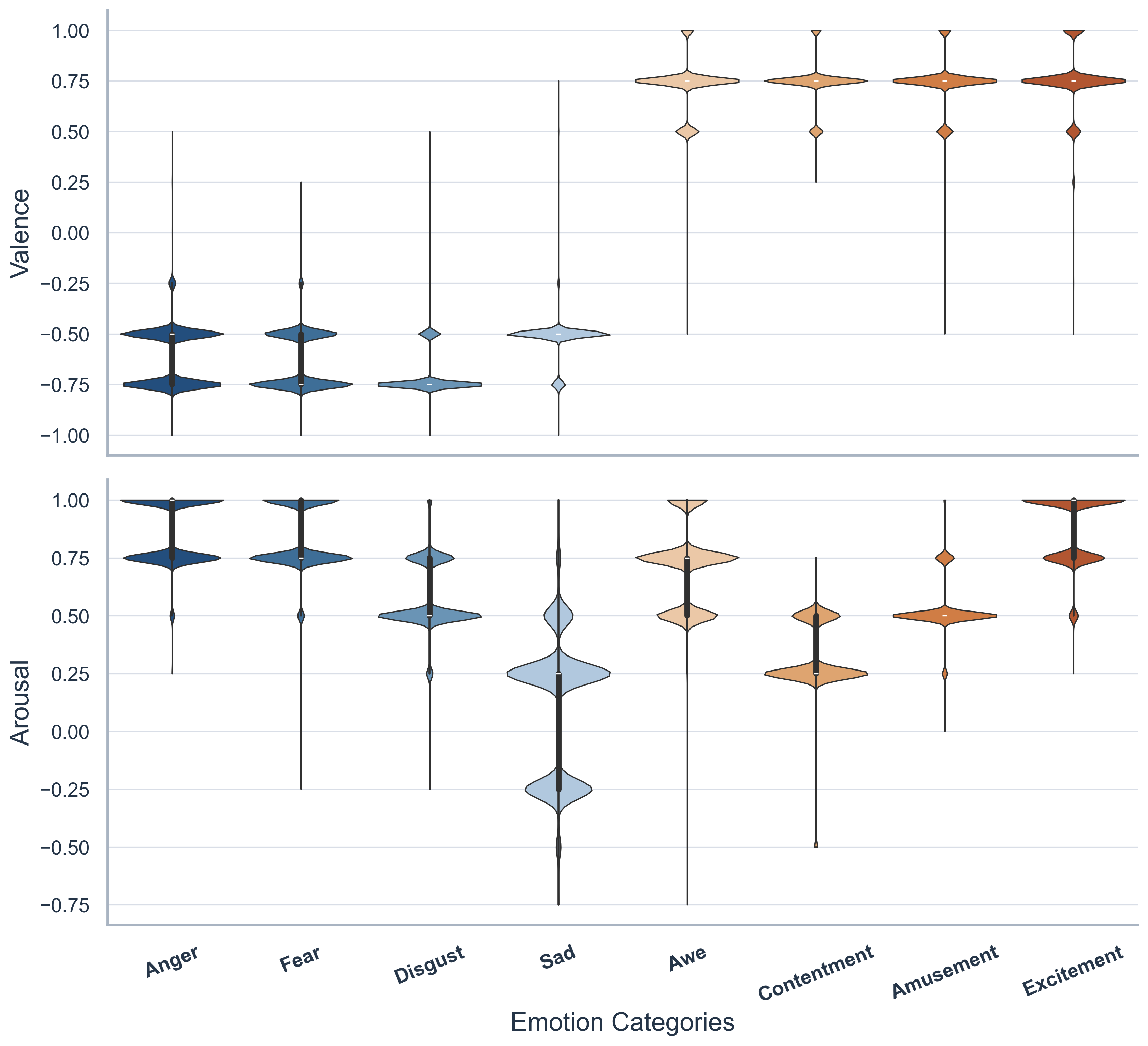
Most overlap appears between nearby affective categories rather than across opposite regions.
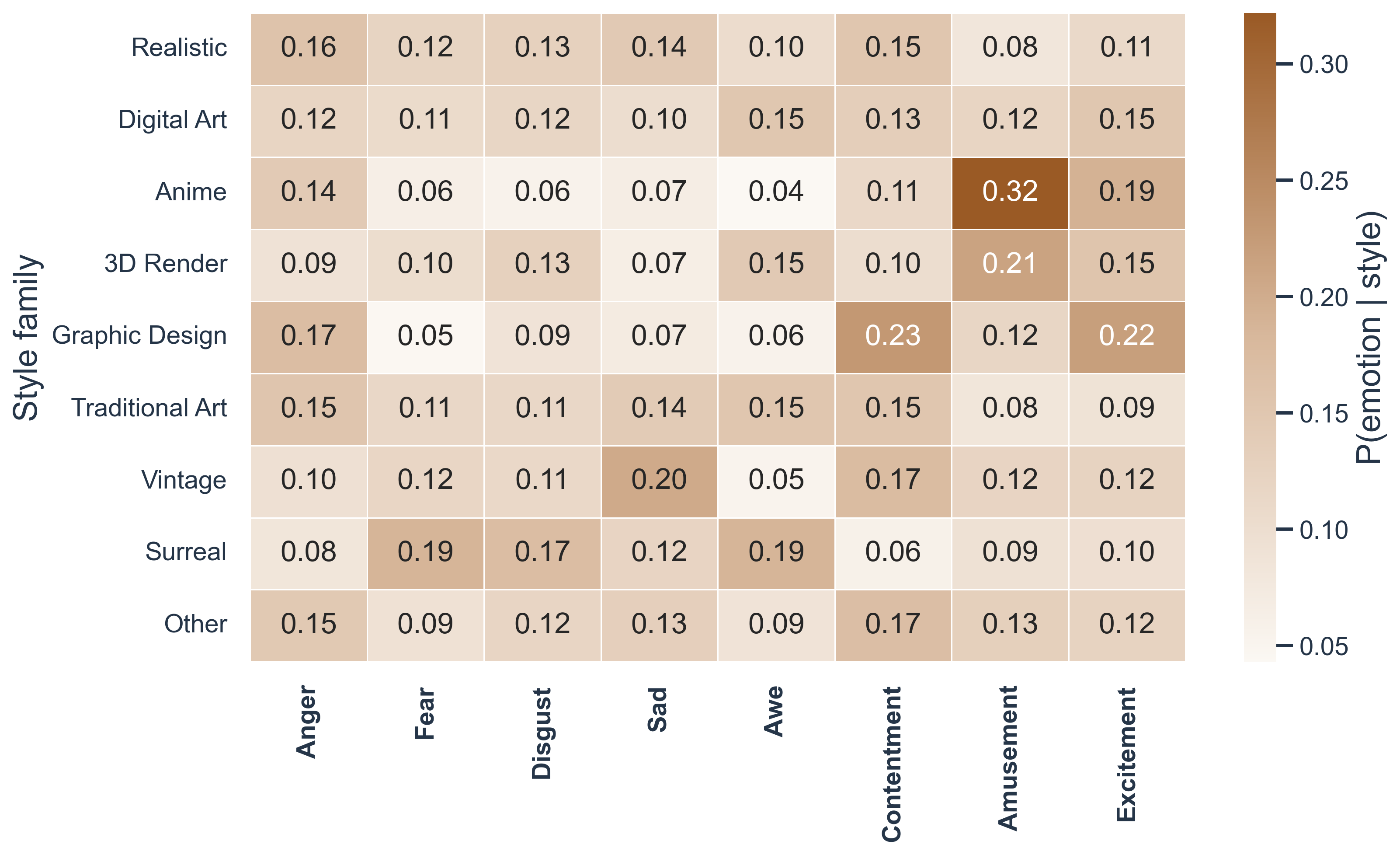
Different style families show distinct emotion preferences, while several major styles remain broadly balanced.
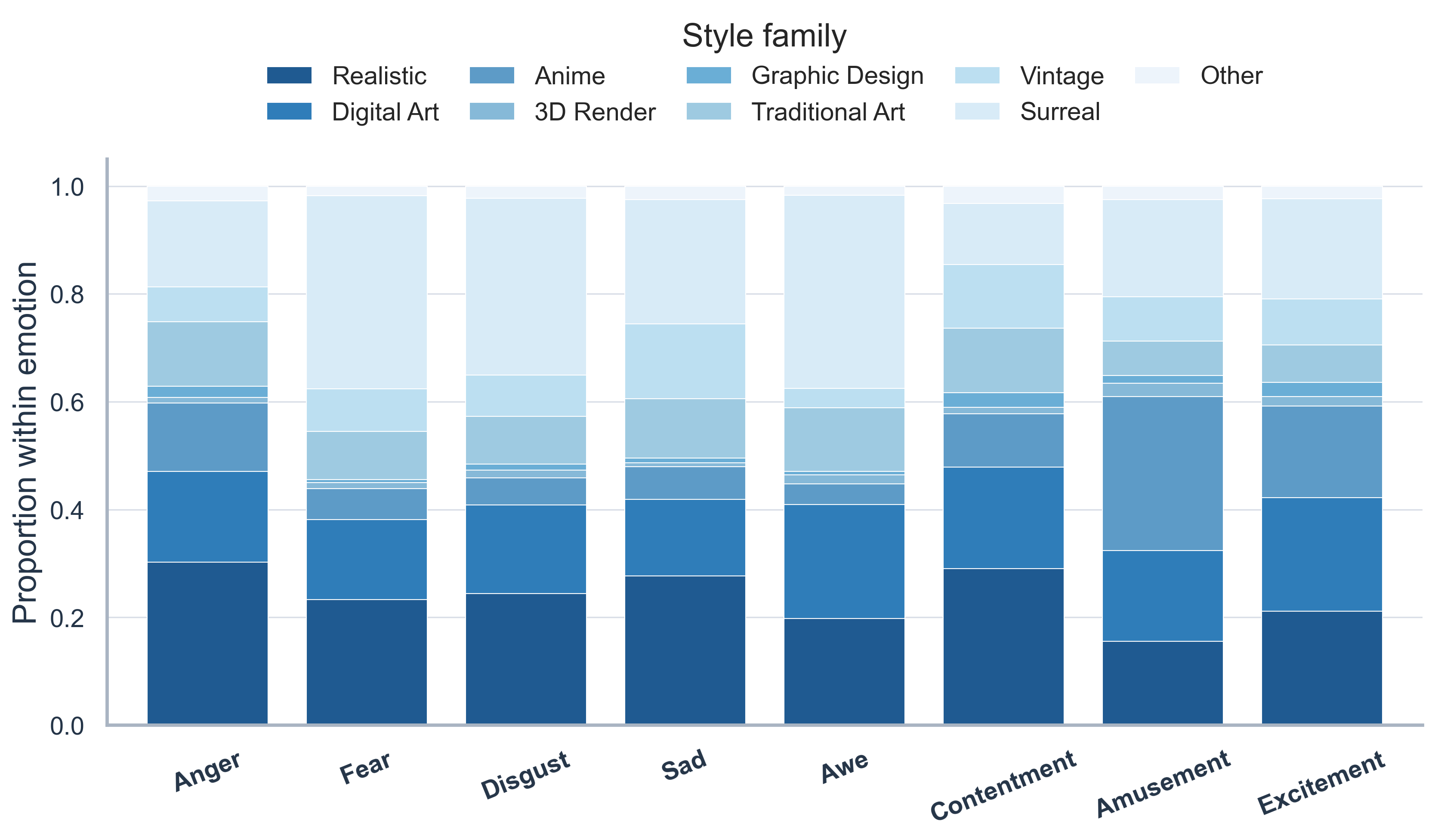
Each emotion category covers multiple styles, but their proportions vary in interpretable ways.
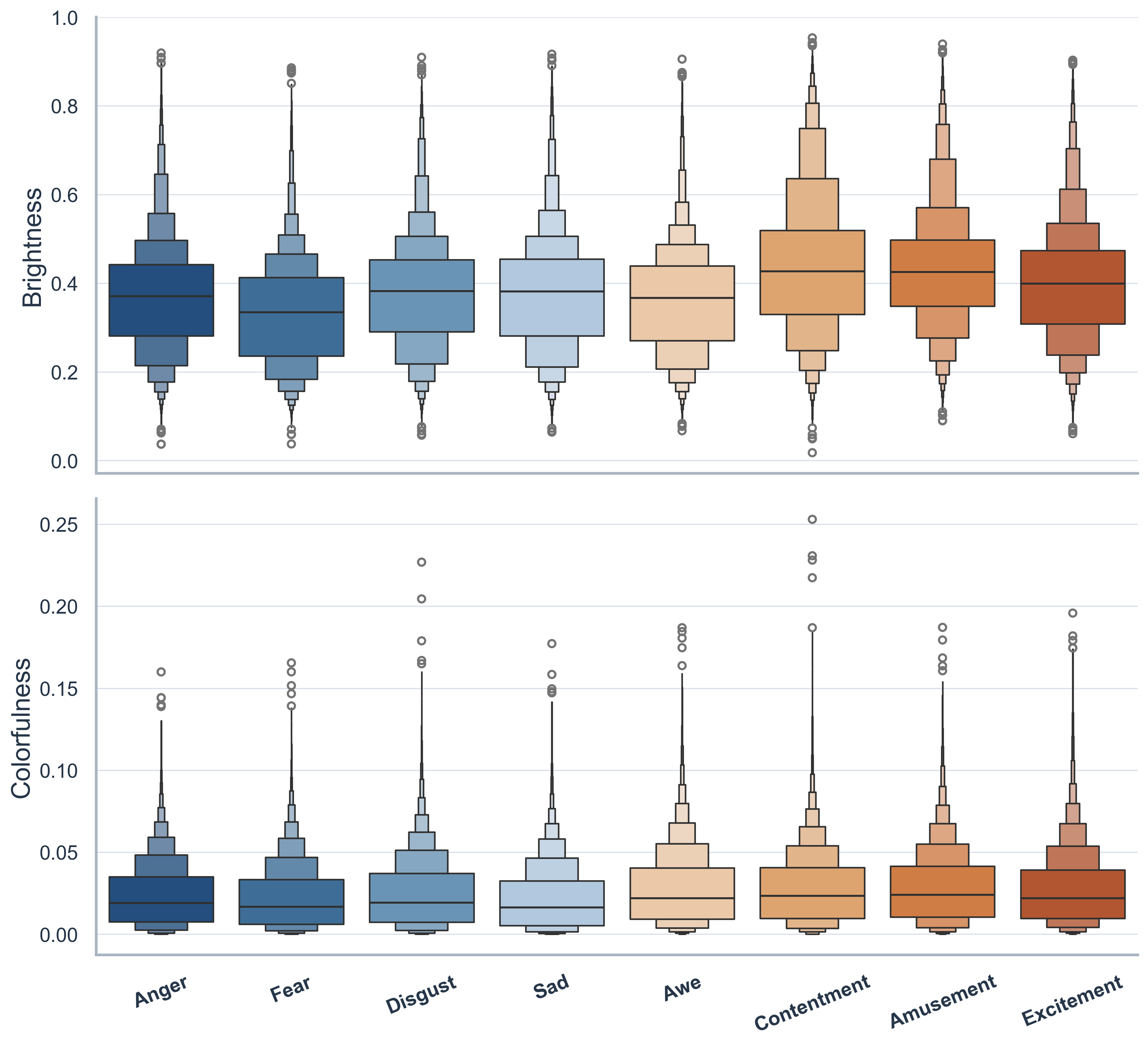
Positive emotions are slightly brighter and more colorful, but overlap remains substantial.
Continuous: ε² = (H - k + 1) / (n - k)
Categorical: V = sqrt(χ² / (n · min(r - 1, c - 1)))
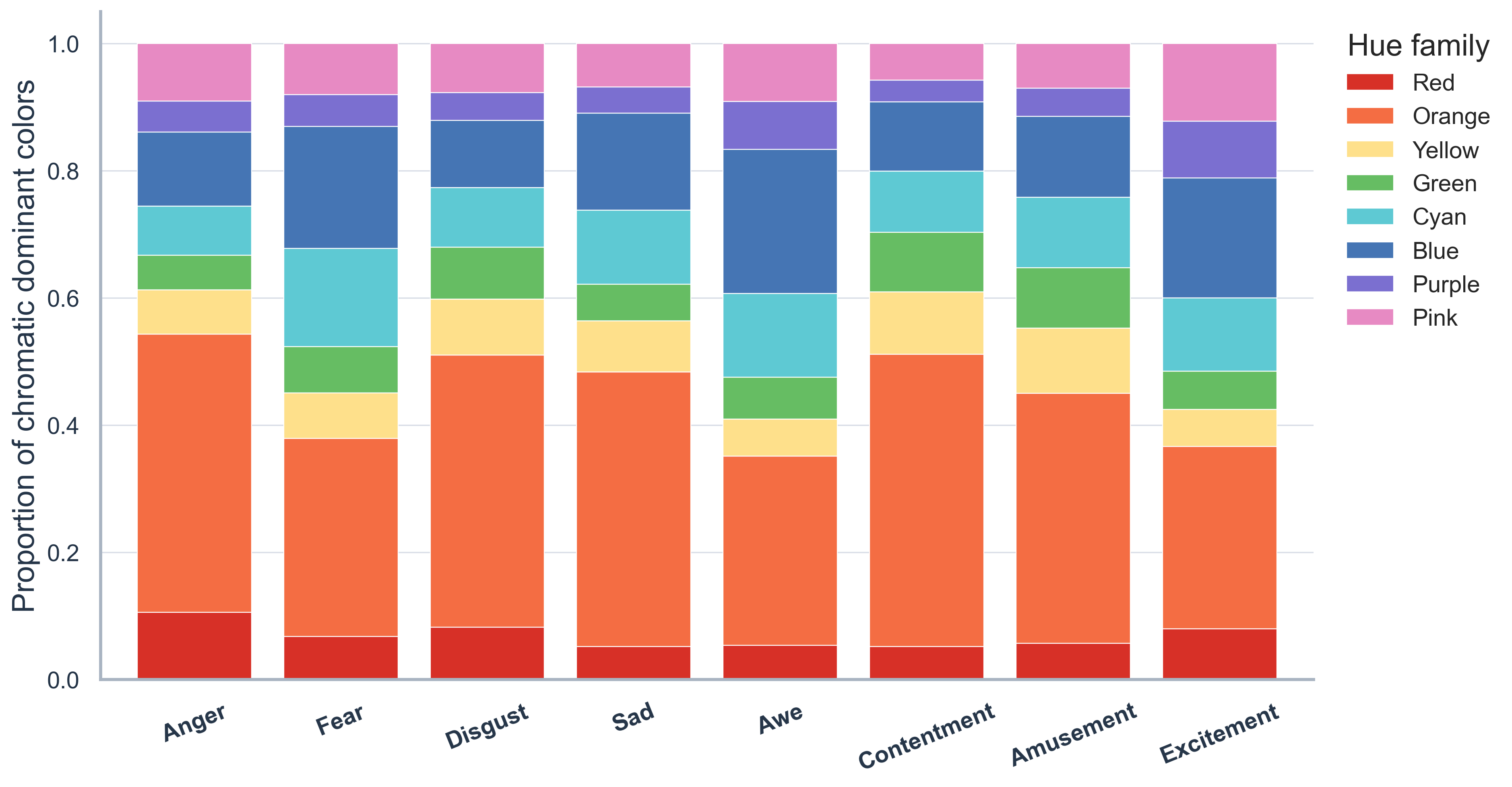
Warm hues dominate across categories, while cool and warm shares vary by emotion.
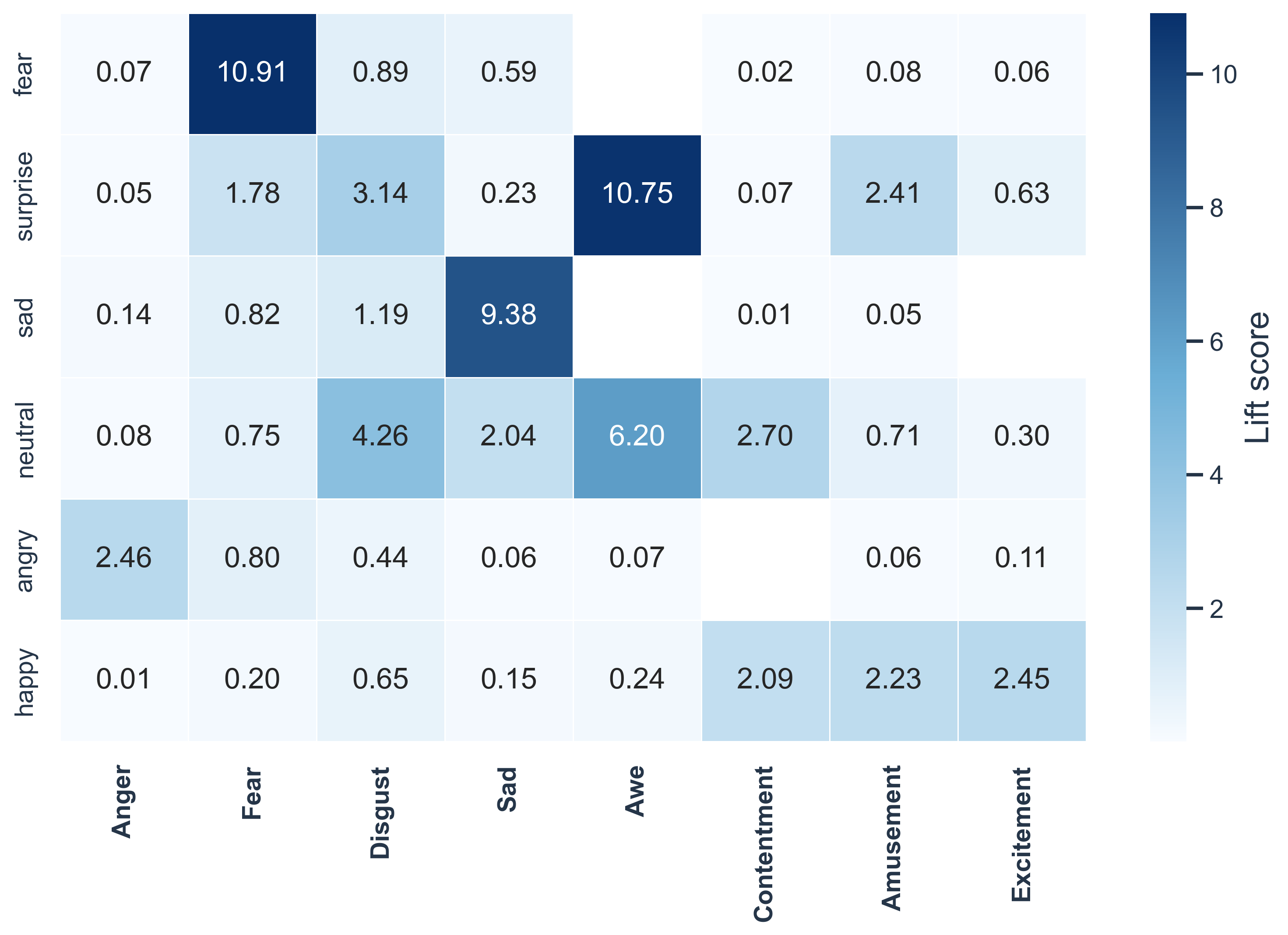
Facial expressions show the clearest emotion-specific enrichment patterns.
Lift(a, e) = P(a | e) / P(a)
Lift above 1 indicates that an attribute is over-represented in that emotion.
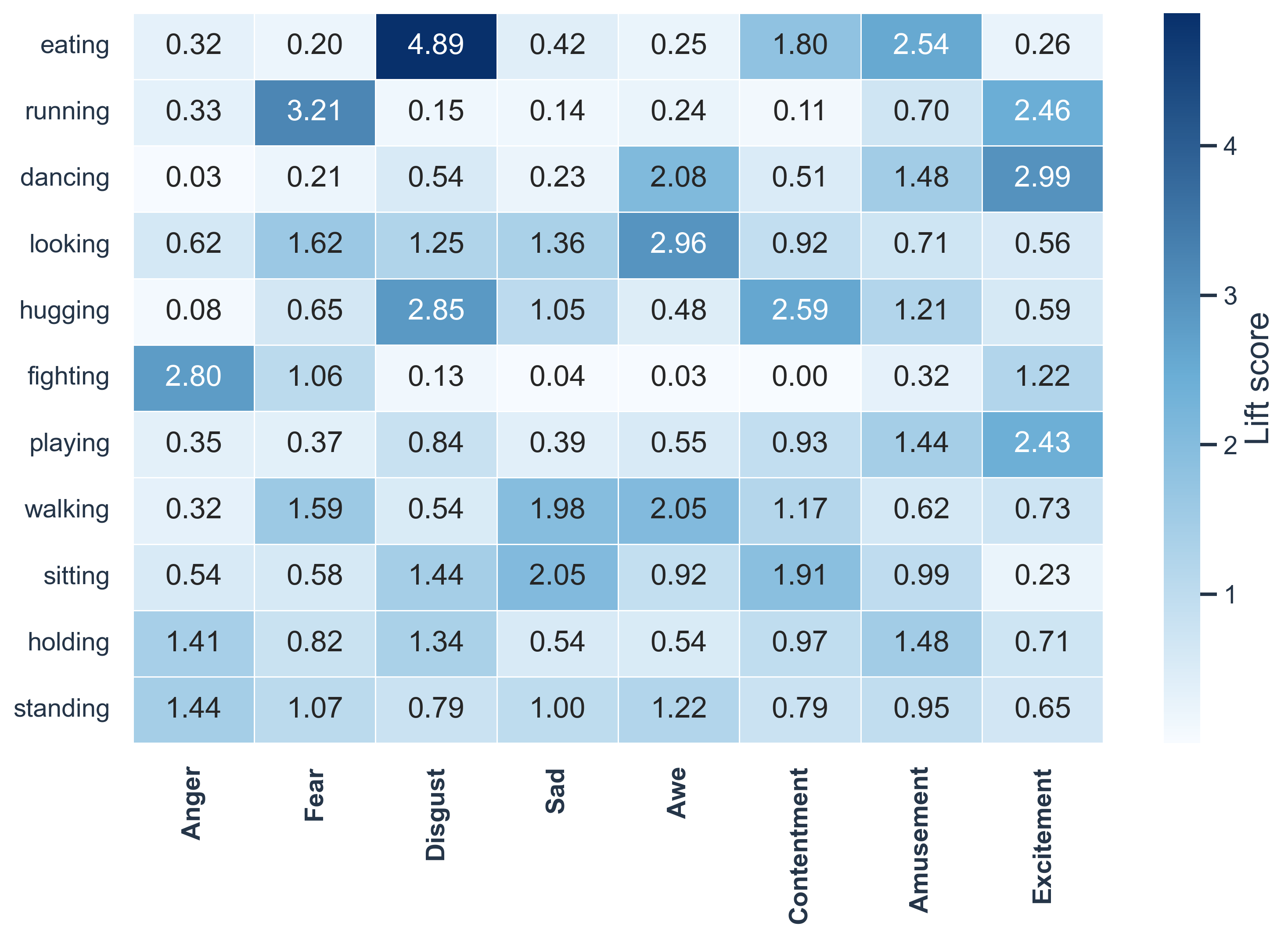
Action categories provide useful behavior-level cues for affective understanding.
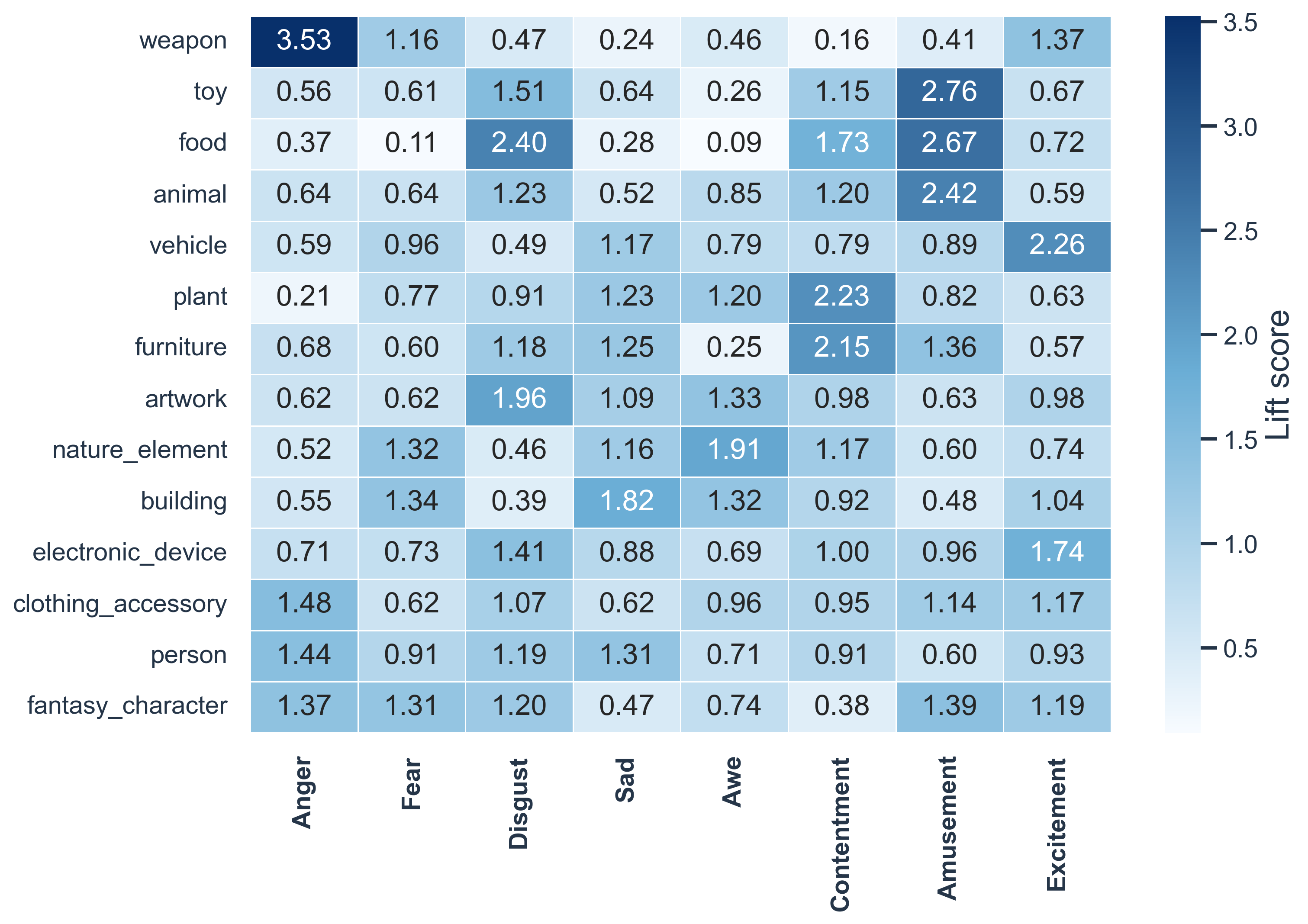
Objects provide diverse semantic grounding, with different categories enriched for different emotions.
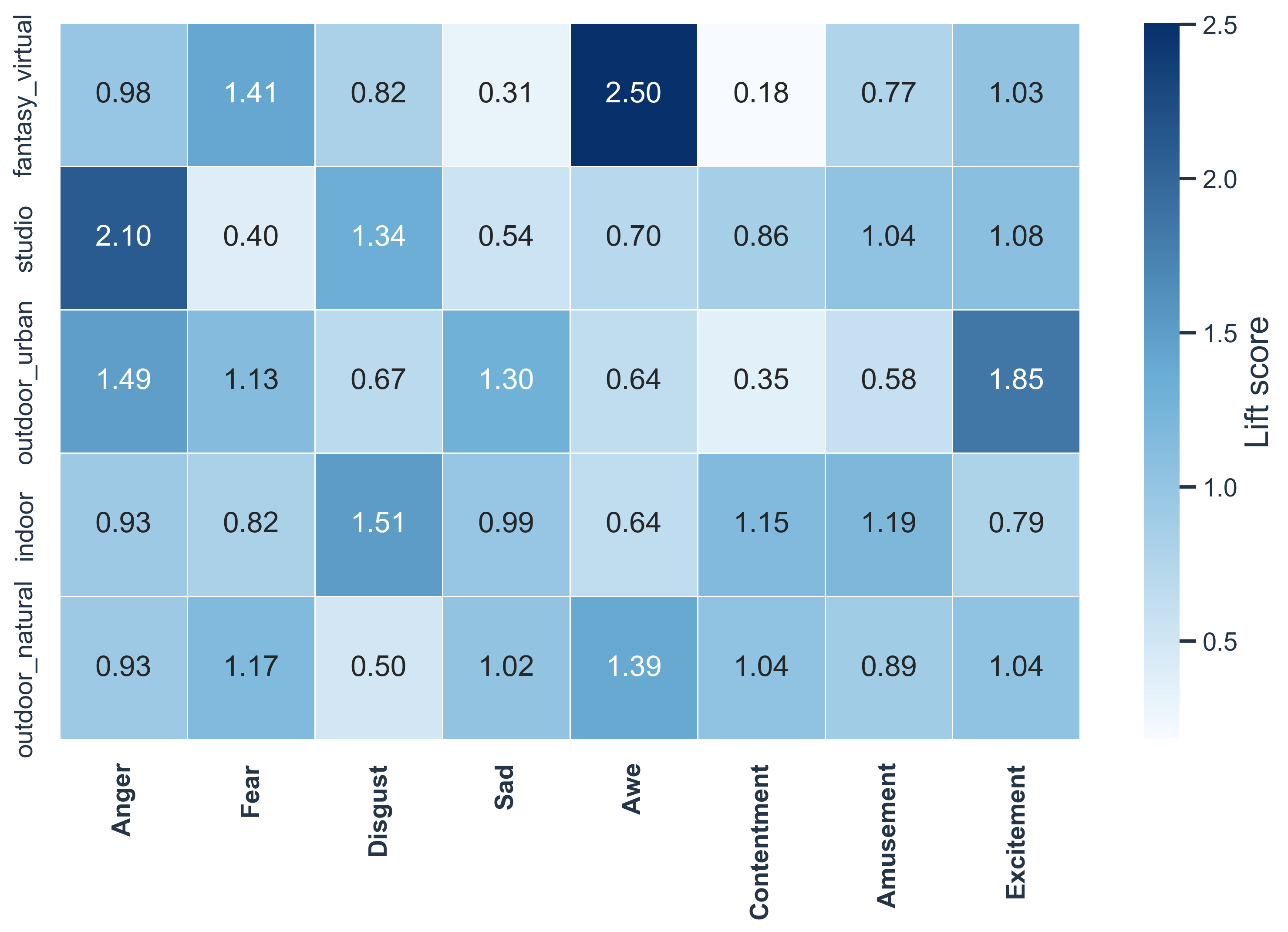
Scene cues are broader than human-centered attributes, but still show coherent emotion-related trends.
We summarize benchmark results for both visual baselines and representative VLMs on AIGIEmo, keeping the tables compact while preserving the full evaluation metrics.
| Model | Acc | F1 | V-MAE | V-PCC | A-MAE | A-PCC |
|---|---|---|---|---|---|---|
| WSCNet | 0.563 | 0.566 | 0.115 | 0.659 | 0.174 | 0.620 |
| StyleNet | 0.569 | 0.572 | 0.112 | 0.665 | 0.171 | 0.629 |
| PDANet | 0.567 | 0.570 | 0.109 | 0.668 | 0.170 | 0.632 |
| Stimuli-Aware | 0.575 | 0.578 | 0.110 | 0.667 | 0.170 | 0.631 |
| MDAN | 0.561 | 0.564 | 0.116 | 0.657 | 0.175 | 0.618 |
| VGG16 | 0.509 | 0.512 | 0.131 | 0.609 | 0.185 | 0.574 |
| ResNet50 | 0.556 | 0.559 | 0.117 | 0.654 | 0.176 | 0.612 |
| DenseNet121 | 0.541 | 0.544 | 0.123 | 0.642 | 0.178 | 0.605 |
| ConvNeXt-T | 0.581 | 0.584 | 0.112 | 0.671 | 0.171 | 0.646 |
| Swin-T | 0.573 | 0.576 | 0.106 | 0.666 | 0.169 | 0.638 |
| ViT-B/16 | 0.528 | 0.531 | 0.118 | 0.632 | 0.178 | 0.610 |
ConvNeXt-T and Swin-T are the strongest visual backbones overall, while earlier VEA-specific models do not show clear advantages on AIGIEmo.
| Ablation Setting | Acc | F1 | V-PCC | A-PCC |
|---|---|---|---|---|
| Full Model | 0.581 | 0.584 | 0.671 | 0.646 |
| w/o Facial Expression | 0.548 | 0.551 | 0.648 | 0.623 |
| w/o Human Action | 0.557 | 0.560 | 0.655 | 0.630 |
| w/o Object | 0.565 | 0.568 | 0.661 | 0.636 |
| w/o Scene | 0.574 | 0.577 | 0.666 | 0.641 |
| w/o All | 0.492 | 0.495 | 0.621 | 0.603 |
Removing auxiliary attributes consistently reduces performance, and the largest drop appears when all attribute cues are removed.
| Model | Emotion Classification | Valence | Arousal | Caption | Reasoning | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Acc (%) | F1 (%) | MAE | PCC | MAE | PCC | BLEU | CIDEr | SPICE | BERTScore | BLEU | CIDEr | SPICE | BERTScore | |
| CLIP | 34.89 | 34.02 | 0.341 | 0.261 | 0.316 | 0.315 | - | - | - | - | - | - | - | - |
| CLIP* | 46.82 | 45.76 | 0.268 | 0.417 | 0.239 | 0.401 | - | - | - | - | - | - | - | - |
| LLaVA-NeXT-7B | 26.64 | 23.51 | 0.299 | 0.382 | 0.265 | 0.342 | 0.050 | 0.072 | 0.090 | 0.883 | 0.042 | 0.059 | 0.074 | 0.881 |
| LLaVA-NeXT-7B* | 41.64 | 38.72 | 0.239 | 0.528 | 0.215 | 0.468 | 0.091 | 0.122 | 0.132 | 0.903 | 0.083 | 0.118 | 0.127 | 0.906 |
| Qwen2-VL-7B | 32.04 | 29.36 | 0.281 | 0.463 | 0.248 | 0.399 | 0.064 | 0.085 | 0.097 | 0.887 | 0.049 | 0.071 | 0.084 | 0.885 |
| Qwen2-VL-7B* | 53.04 | 50.88 | 0.215 | 0.624 | 0.189 | 0.556 | 0.100 | 0.129 | 0.137 | 0.905 | 0.089 | 0.124 | 0.131 | 0.907 |
| Qwen2.5-VL-7B | 34.60 | 30.84 | 0.262 | 0.502 | 0.231 | 0.438 | 0.071 | 0.091 | 0.102 | 0.889 | 0.052 | 0.079 | 0.092 | 0.887 |
| Qwen2.5-VL-7B* | 52.00 | 49.31 | 0.213 | 0.617 | 0.187 | 0.549 | 0.104 | 0.135 | 0.140 | 0.908 | 0.095 | 0.130 | 0.138 | 0.909 |
| GLM-4.6V-Flash | 30.96 | 27.83 | 0.254 | 0.550 | 0.224 | 0.480 | 0.078 | 0.093 | 0.105 | 0.888 | 0.057 | 0.081 | 0.090 | 0.888 |
| GLM-4.6V-Flash* | 44.93 | 42.81 | 0.215 | 0.613 | 0.194 | 0.553 | 0.101 | 0.127 | 0.138 | 0.904 | 0.091 | 0.120 | 0.129 | 0.906 |
| InternVL3.5-8B | 35.16 | 22.15 | 0.251 | 0.405 | 0.211 | 0.386 | 0.057 | 0.069 | 0.093 | 0.886 | 0.049 | 0.093 | 0.101 | 0.892 |
| InternVL3.5-8B* | 47.58 | 44.26 | 0.208 | 0.493 | 0.182 | 0.449 | 0.096 | 0.122 | 0.134 | 0.904 | 0.089 | 0.116 | 0.133 | 0.907 |
| Qwen3-VL-8B | 35.17 | 21.73 | 0.239 | 0.447 | 0.215 | 0.414 | 0.079 | 0.101 | 0.093 | 0.883 | 0.053 | 0.078 | 0.067 | 0.881 |
| Qwen3-VL-8B* | 48.71 | 45.39 | 0.202 | 0.528 | 0.187 | 0.475 | 0.108 | 0.136 | 0.139 | 0.905 | 0.097 | 0.125 | 0.134 | 0.908 |
| Step3-VL-10B | 31.82 | 28.98 | 0.261 | 0.465 | 0.235 | 0.325 | 0.045 | 0.073 | 0.103 | 0.881 | 0.004 | 0.036 | 0.038 | 0.813 |
| Step3-VL-10B* | 43.88 | 40.72 | 0.226 | 0.544 | 0.204 | 0.393 | 0.083 | 0.109 | 0.122 | 0.897 | 0.071 | 0.099 | 0.111 | 0.899 |
Fine-tuning on AIGIEmo consistently improves VLM performance across emotion, V-A, caption, and reasoning tasks. Among the reported adapted settings, Qwen2-VL-7B* achieves the strongest overall benchmark result.
We further evaluate whether AIGIEmo provides useful supervision beyond existing VEA data, both under controlled data mixing and cross-dataset transfer.
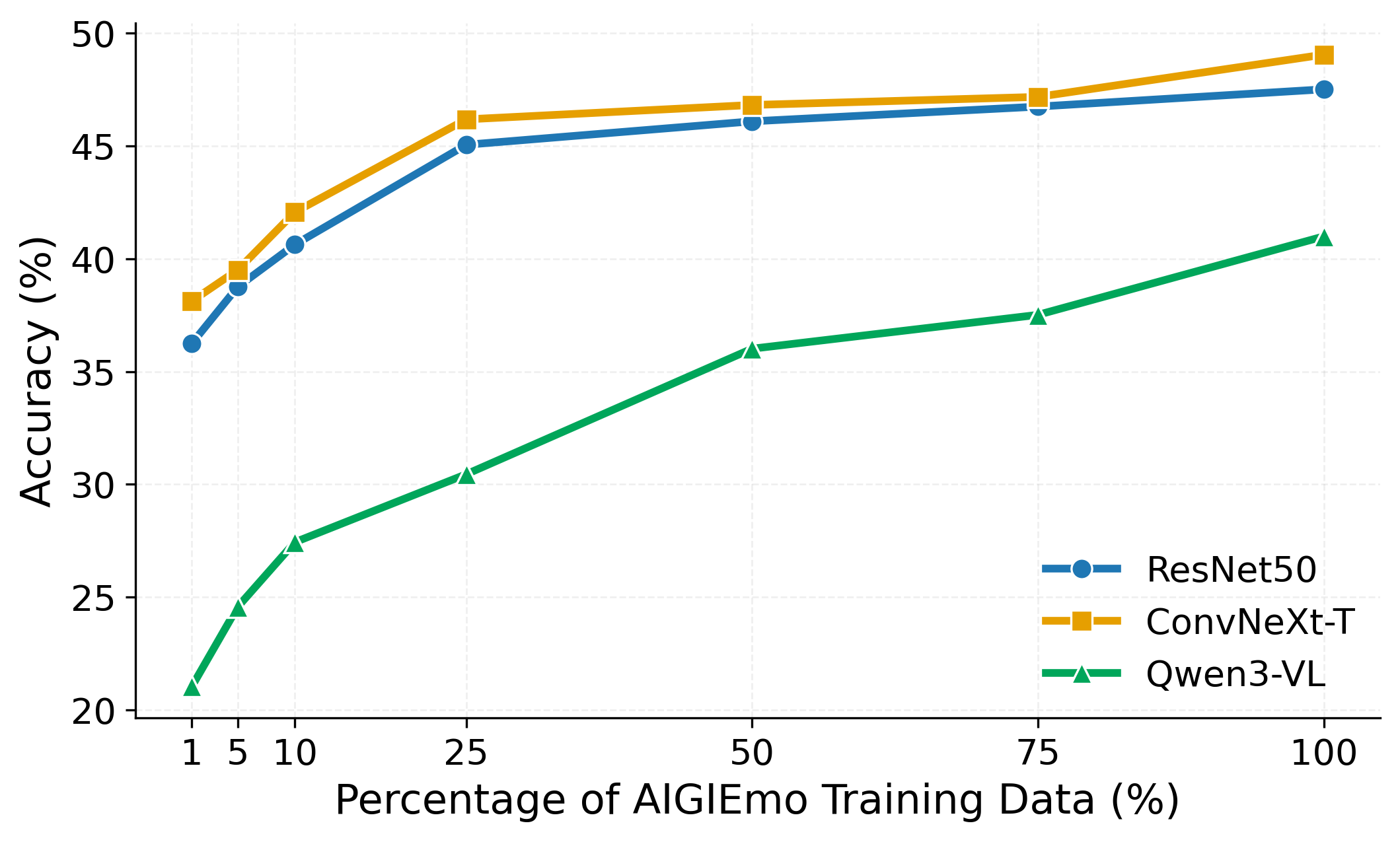
Starting from EmoSet as the base training set, adding more AIGIEmo data steadily improves ResNet50, ConvNeXt-T, and Qwen3-VL on the AIGIEmo test split.
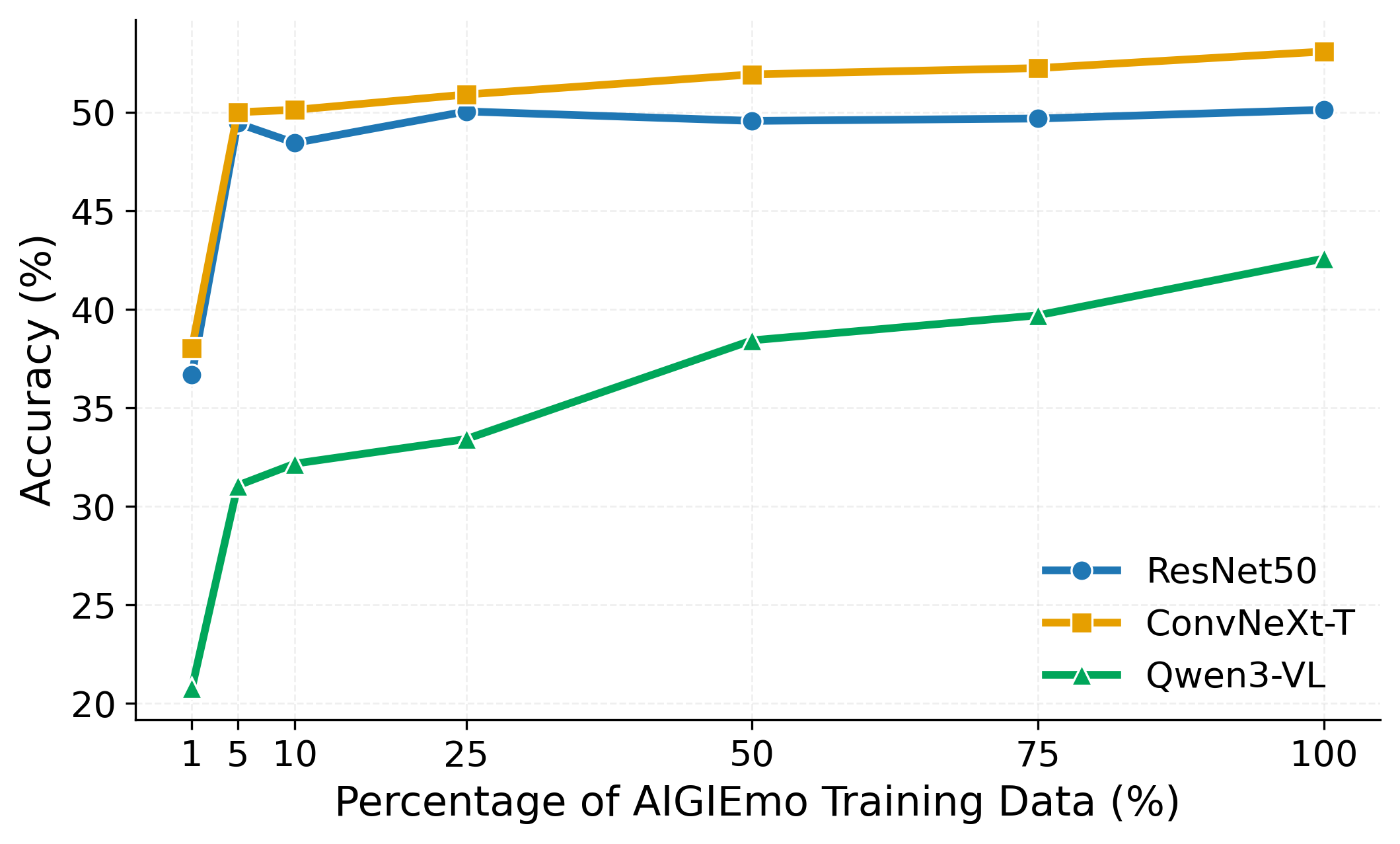
The same mixing strategy also improves performance on AIGI-VC, showing that AIGIEmo contributes useful supervision beyond its own in-domain benchmark.
| Train \ Test | AIGIEmo | AIGI-VC |
|---|---|---|
| AIGIEmo | 0.581 | 0.620 |
| AIGI-VC | 0.495 | 0.592 |
| Train \ Test | AIGIEmo | EmoSet |
|---|---|---|
| AIGIEmo | 0.581 | 0.426 |
| EmoSet | 0.412 | 0.782 |
Together, these results show that AIGIEmo is not only a strong in-domain dataset, but also a practically useful source of transferable supervision for emotion recognition on AI-generated images.
AIGIEmo supports supervised learning and benchmark evaluation for categorical emotion classification and dimensional affect prediction on AI-generated images.
Human-finalized captions and emotion reasoning make AIGIEmo suitable for affective caption generation, emotion explanation, and language-grounded affective understanding.
The combination of prompts, images, auxiliary attributes, captions, and reasoning supports prompt-aware emotion prediction, affect alignment, and human-centered interpretation of generated content.
AIGIEmo can support research on dataset bias, human-AI affective agreement, prompt-driven emotion control, and human-centered evaluation of AIGI systems.
Zhanpeng Jin
zjin@scut.edu.cn
Yang Gao
gaoyang2025@scut.edu.cn
Dong She
ftdshe@mail.scut.edu.cn
Cong Liu
202420163862@mail.scut.edu.cn
Nuo Chen
202230310052@mail.scut.edu.cn